Small-Team Public Web Monitoring: Scrapingbypass API vs Maintaining Browsers: Public Documentation Checks for Daily Workflows
Bottom line: Direct fetch is enough for stable low-risk pages. Scrapingbypass API becomes more useful when monitoring jo...

Resolve modern WAF challenges: Handle Cloudflare JS Challenge, Turnstile CAPTCHA, browser checks, and Imperva/Incapsula-style verification so data requests can reach protected pages more consistently.
Rotating proxy network included: Use global residential proxies, datacenter proxies, HTTP/SOCKS5 routing, or your own proxy provider to match country, session, and reputation requirements.
Browser fingerprint alignment: Tune TLS JA3/JA4 fingerprints, Canvas signals, User-Agent, Referer, and headless browser traits to reduce bot-detection mismatches.
Easy integration for every stack: Call the HTTP API from cURL, Python, Go, Node.js, or Java. Built for scraping teams, AI agents, monitoring jobs, and automation pipelines.
Protocol-level speed advantage: Replace heavy local browsers with optimized API requests that return verified HTML or JSON, improving throughput while lowering compute and bandwidth cost.
Start Free Trial API DOCs Code generator
Visit https://opensea.io/path/to/target?a=4, the following is an example of Curl request:
# Use curl to request https://opensea.io/category/memberships
# curl -X GET "https://opensea.io/category/memberships"
#Using Scrapingbypass API request example
# Use Cloudbyapss API to request
curl -X GET "https://api.cloudbypass.com/category/memberships" ^
-H "x-cb-apikey: YOUR_API_KEY" ^
-H "x-cb-host: opensea.io" -k
# Use CloudbypassProxy request example
# Use Cloudbyapss Proxy to request
curl -X GET "https://opensea.io/category/memberships" -x "http://YOUR_API_KEY:@proxy.cloudbypass.com:1087" -k
Detailed documentation
Visit https://opensea.io/path/to/target?a=4, the following is an example of Python request:
// Use python to request https://opensea.io/category/memberships
import requests
"""
# Code example before modification
# original code
url = "https://opensea.io/category/memberships"
response = requests.request("GET", url)
print(response.text)
print(response.status_code,response.reason)
# (403, 'Forbidden')
"""
#Using Scrapingbypass API request example
# Use Cloudbyapss API to request
url = "https://api.cloudbypass.com/category/memberships"
headers = {
'x-cb-apikey': 'YOUR_API_KEY',
'x-cb-host': 'opensea.io',
}
response = requests.request("GET", url, headers=headers)
print(response.text)
// Use python to request https://opensea.io/category/memberships
import requests
"""
# Code example before modification
# original code
url = "https://opensea.io/category/memberships"
response = requests.request("GET", url)
print(response.text)
print(response.status_code,response.reason)
# (403, 'Forbidden')
"""
#Using Scrapingbypass API request example
# Use Cloudbyapss API to request
url = "https://api.cloudbypass.com/category/memberships"
headers = {
'x-cb-apikey': 'YOUR_API_KEY',
'x-cb-host': 'opensea.io',
}
response = requests.request("GET", url, headers=headers)
print(response.text)
Detailed documentation
Access https://opensea.io/category/memberships, request example:
// # Go Modules
// require github.com/go-resty/resty/v2 v2.7.0
package main
import (
"fmt"
"github.com/go-resty/resty/v2"
)
func main() {
client := resty.New()
client.Header.Add("X-Cb-Apikey", "/* APIKEY */")
client.Header.Add("X-Cb-Host", "opensea.io")
resp, err := client.R().Get("https://api.cloudbypass.com/category/memberships")
if err != nil {
fmt.Println(err)
return
}
fmt.Println(resp.StatusCode(), resp.Header().Get("X-Cb-Status"))
fmt.Println(resp.String())
}
Detailed documentation
Visit https://opensea.io/path/to/target?a=4, the following is an example Nodejs request:
// Use javascript to request https://opensea.io/category/memberships
const axios = require('axios');
/*
// Code example before modification
//original code
const url = "https://opensea.io/category/memberships";
axios.get(url, {})
.then(response => console.log(response.data))
.catch(error => console.error(error));
*/
// Example of request using Scrapingbypass API
// Use Cloudbyapss API to request
const url = "https://api.cloudbypass.com/path/to/target?a=4";
const headers = {
'x-cb-apikey': 'YOUR_API_KEY',
'x-cb-host': 'www.example.com',
};
axios.get(url, {}, {headers: headers})
.then(response => console.log(response.data))
.catch(error => console.error(error));
# Use javascript to request https://opensea.io/category/memberships
const axios = require('axios');
//Request example using CloudbypassProxy
// Use Cloudbyapss Proxy to request
const url = "https://opensea.io/category/memberships";
const config = {
proxy: {
host: 'proxy.cloudbypass.com',
port: 1087,
auth: {
username: 'YOUR_API_KEY',
password: ''
// Use a custom proxy
// password: 'proxy=http:CUSTOM_PROXY:8080'
}
}
};
axios.get(url, config)
.then(response => console.log(response.data))
.catch(error => console.error(error));
Detailed documentation
Visit https://opensea.io/path/to/target?a=4, the following is a Java request example:
// Use java to request https://opensea.io/category/memberships
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
public class Main {
public static void main(String[] args) throws Exception {
/*
// Code example before modification
//original code
String url = "https://opensea.io/category/memberships";
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(url))
.GET(HttpRequest.BodyPublishers.noBody())
.build();
HttpResponse response = client.send(request, HttpResponse.BodyHandlers.ofString());
System.out.println(response.body());
*/
// Example of request using Scrapingbypass API
// Use Cloudbyapss API to request
String url = "https://api.cloudbypass.com/category/memberships";
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(url))
.header("x-cb-apikey", "YOUR_API_KEY")
.header("x-cb-host", "opensea.io")
.GET(HttpRequest.BodyPublishers.noBody())
.build();
//Request example using CloudbypassProxy
// Use Cloudbyapss Proxy to request
String url = "https://opensea.io/category/memberships";
HttpClient client = HttpClient.newBuilder()
.proxy(HttpClient
.ProxySelector
// Use a custom proxy
//.of(URI.create("http://YOUR_API_KEY:proxy=http:CUSTOM_PROXY:[email protected]:1087")))
.of(URI.create("http://YOUR_API_KEY:@proxy.cloudbypass.com:1087")))
.build();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(url))
.GET()
.build();
HttpResponse response = client.send(request, HttpResponse.BodyHandlers.ofString());
System.out.println(response.body());
}
}
Detailed documentation
Register a Scrapingbypass API account - Sign Up Now
Register a Scrapingbypass Proxy account - Sign Up Now
One registration gives you access to both API and Proxy products. Log in within 30 days and click Trial Activity to claim test credits and proxy traffic.
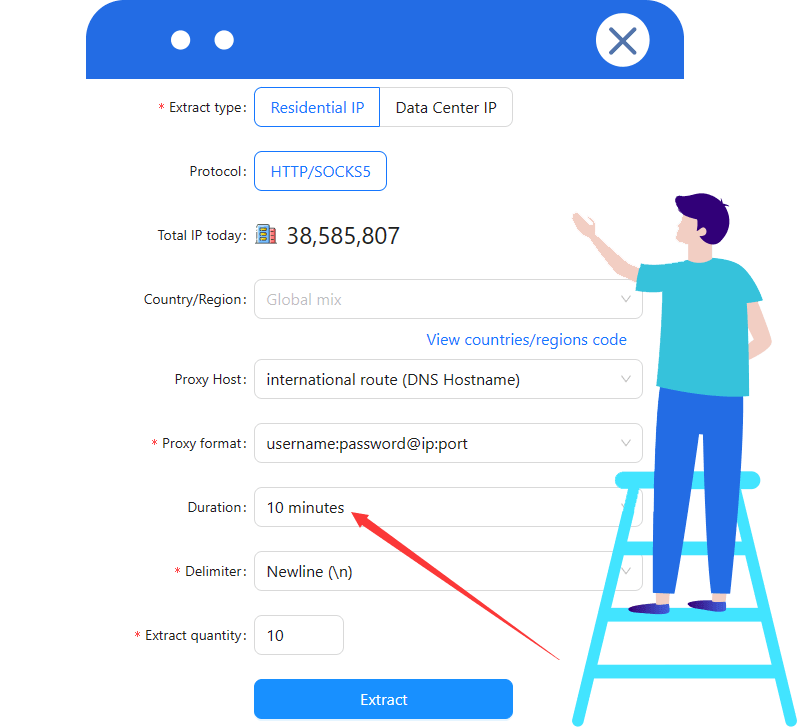
Enter your target URL in the Code Generator to test whether the target page needs WAF bypass, proxy routing, sticky sessions, or extra headers.
V1 includes a built-in rotating IP pool - no proxy setup is required if accessible.
V2 requires a fixed or time-based IP. When using Scrapingbypass rotating IPs, set validity to at least 10 minutes.
For assistance, see the API documentation or contact Scrapingbypass Support.
Add the API to your crawler, job queue, or AI automation agent, then validate response status, headers, proxy strategy, and parsing logic before production.
Choose API credits or proxy traffic based on request volume, target protection level, and session duration - View Pricing
To handle Cloudflare's JS Challenge, purchase a credit plan.
For proxy traffic, select a Rotating Datacenter or Rotating Residential proxy plan.
Cloudflare bypass consumes points and may require proxy support. A proxy alone cannot bypass Cloudflare.

Scrapingbypass API focuses on the hardest part of modern web scraping: passing anti-bot verification before your parser ever sees the page. It handles Cloudflare JS Challenge, Turnstile CAPTCHA, browser checks, and protocol fingerprints so your crawler can keep returning useful HTML or JSON.
Auto-solves complex challenges and matches real browser behavior.
Decrypts and formats responses so you get structured data faster.
Customize Referer and headers to fit the target verification flow.
Send business data via JSON payloads or form parameters.
Handle URL query parameters for search, paging, and filtering.
Use external proxy IP and rotating IP pools for geo-matching access.
Scrapingbypass exposes WAF bypass and proxy routing as standard HTTP requests. Add a few headers, keep your existing scraper framework, and avoid maintaining custom challenge solvers, browser farms, and fingerprint patches.
Test with native cURL in one command to verify Cloudflare challenge handling, with minimal setup.
Works with requests and aiohttp for async high concurrency - ideal for data extraction teams.
Leverages Go concurrency with fast, type-safe APIs for large-scale scraping workloads.
Fits full-stack apps and automation tools, enabling fast request routing in services or scripts.
Built for enterprise standards, supports multithreaded calls for steady access in complex flows.
Includes full type definitions to improve reliability across modern web scraping pipelines.
Modern WAFs compare far more than IP reputation. Scrapingbypass aligns TLS fingerprints, HTTP/2 behavior, browser headers, and device-like signals so automated requests look consistent across the full session, reducing 403, 429, and challenge-loop failures.
Syncs updates fast and supports protocol-level handling for new bot checks.
Supports JS Challenge and tough Cloudflare Turnstile for web scraping tasks.
Mimics traffic source paths for sites with strict origin validation.
Large real-device UA pool for desktop and mobile, with easy switching.
Works with Web Application Firewall (WAF) and CDN protection layers, including Imperva and Akamai.
Protocol-level headless browser simulation with JavaScript rendering efficiency for faster data extraction.
Compared with heavy Selenium/Puppeteer setups, Scrapingbypass API uses a protocol-based request mode with no real browser instance. This keeps server usage low while supporting high concurrency across OS and cloud environments.
Fits Windows workflows for local debugging and fast delivery of small-to-mid data extraction jobs.
Works smoothly on Apple Silicon, making scripting, testing, and iteration faster for developers.
Optimized for mainstream Linux, with Docker deployments and horizontal cluster scaling.
Meets enterprise stability needs and runs long-term in traditional IDC environments.
Supports mobile protocol forwarding for iOS testing and mobile data extraction access.
Fits Android API calls and helps automated access pass cloud firewall checks reliably.









|
|
Covers marketplaces and DTC websites. Track new listings, benchmark competitors, monitor pricing and promotions, and analyze review and demand trends - helping teams react faster and optimize product and pricing decisions. |

|
|
Built for growth and performance teams. Continuously track competitor ad creatives, landing page changes, and keyword trends - turning signals into reusable insights for strategy reviews and campaign optimization. |

|
|
Capture feeds and engagement signals across social platforms. Track trends, analyze topics, shortlist creators, and monitor sentiment - so teams can identify what's working and scale content more efficiently. |

|
|
Designed for asset archiving and creative reuse. Organize video and image libraries with tags, track performance signals, and build a searchable reference hub - speeding up production and improving consistency. |

|
|
Aggregate updates from news and content platforms. Track breaking events, build topic collections, and sync chapters/releases - creating structured content assets for recommendations, operations, and research. |

|
|
Cover stocks, indices, FX rates, commodities, and crypto markets. Collect real-time and historical prices, candlestick indicators, and event/news signals - supporting backtests, alerts, and quant workflows. |

|
|
Collect job listings and hiring signals across platforms and company sites. Track demand, skills, and salary movements - supporting recruiting planning, workforce insights, and industry research. |

|
|
Consolidate listings and local service data for market monitoring and location analysis. Track supply, demand, and pricing shifts - helping teams make faster, more confident decisions in local operations. |

|
|
Built for travel services and industry analysts. Track flights, hotels, ticketing, and visa rules in one place - even when prices and policies change frequently - so your data stays reliable for planning and decisions. |

|
|
Collect coupon and promotion data across channels. Track promo trends, evaluate offer effectiveness, monitor expiry changes, and analyze post-discount pricing - helping teams compare campaigns and improve conversion performance. |

|
|
Track ocean routes and schedules, port milestones, container movements, and freight surcharges. Enable shipment visibility and exception alerts - so teams can forecast costs and delivery performance with confidence. |

|
|
Built for fraud prevention and security operations. Aggregate risk IPs/domains, abnormal behavior signals, and reputation intelligence - powering faster assessments, automated alerts, and stronger protection boundaries. |
Each successful API request consumes credits, while failed requests do not deduct any credits.
V1: Each successful request consumes 1 credit.
V2: Each successful request consumes 3 credits. One credit is used for the API request itself, and two additional credits are consumed during JavaScript polling.
The session remains valid for 10 minutes. During this period, the same proxy and session parameters can be reused to avoid repeated Cloudflare verification.
This means no additional credits are charged for subsequent requests within the same session window.
Scrapingbypass API credits expire if not used within their validity period.
Each recharge is calculated independently, and credits are consumed on a first-in, first-out basis.
Scrapingbypass operates as a request-forwarding service. You submit an HTTP request to the Scrapingbypass API, and the API executes the request on your behalf. This approach significantly reduces the likelihood of your traffic being identified as automated. The system focuses on preventing Cloudflare challenges from being triggered, allowing direct access to the target URL instead of programmatically interacting with challenge pages.
The Scrapingbypass API is designed to be simple and developer-friendly.
You only need to submit the HTTP request intended for the target website, and Scrapingbypass will forward it exactly as provided.
You can use the online code generator to generate request examples in cURL, JavaScript, TypeScript, Java, Python, and more.
Scrapingbypass API and Proxy integration examples are available here:
View code examples
Scrapingbypass V2 supports JavaScript rendering and polling, making it suitable for more advanced Cloudflare challenges.
V2 does not include a default proxy. You must use a Scrapingbypass Proxy with V2.
V1 includes a built-in rotating proxy by default.
Session partitions are used to manage Cloudflare cookies and verified sessions.
Once a session is successfully verified, the proxy IP, browser fingerprint, and related parameters must remain unchanged for 10 minutes.
This prevents additional Cloudflare challenges from being triggered during the session.
Session partition values range from 0 to 999, allowing up to 1,000 concurrent session partitions per account.
After a successful request, the proxy IP is locked to the session partition.
Changing the partition value allows you to switch proxies.
Each successful request refreshes the 10-minute session duration.
Start by testing your target URL using the
code generator with Scrapingbypass V1.
If V1 fails, switch to Scrapingbypass V2 and configure your own proxy IP.
A test proxy is available in the backend for validation.
It is recommended to set the proxy extraction duration to more than 10 minutes.
All Scrapingbypass API plans currently support up to 30 concurrent requests per second.
This error indicates that your Scrapingbypass API account has no remaining credits.
You can purchase credits in the Scrapingbypass API console:
Scrapingbypass API Console,
or contact customer support to request test credits.
Error description:
This error occurs when the current session partition is already processing a Cloudflare challenge.
Common causes:
The same session partition is used concurrently by multiple threads.
Multiple users are operating on the same account and partition.
A previous request is still holding the verification lock.
Recommended solutions:
Wait for the lock to be released and retry the request.
Switch to a different session partition (range: 0-99).
Recommended actions:
1. Set the proxy IP extraction duration to at least 10 minutes.
2. Switch to proxy IPs from different countries or regions.
Using IPs from the same region repeatedly may increase the risk of restriction.
These errors usually indicate that a proxy is required. You can use either API mode or Proxy mode to access Scrapingbypass services. API mode is recommended for domestic users. Currently, only HTTP proxies are supported.
Browser automation tools such as Selenium and Puppeteer are not supported. Scrapingbypass operates at the HTTP request level and simulates browser requests without launching a real browser.
Scrapingbypass does not use monthly subscriptions. All Scrapingbypass Proxy services follow a traffic-based pricing model with no expiration. You can purchase traffic packages on demand, and unused bandwidth will never expire.
Scrapingbypass Proxy supports multiple payment methods, including Alipay, USDT, and other supported options depending on your region.
For Scrapingbypass Rotating Proxies, traffic usage is calculated based on the total volume of uploaded and downloaded data through the proxy connection.
IP geolocation results may vary depending on the detection database used. Please verify the proxy IP location using the official Scrapingbypass IP check tool: http://ipinfo.cloudbypass.com .
Scrapingbypass offers two core proxy networks: Rotating Residential Proxies and Rotating Datacenter Proxies. Both proxy types are designed for Cloudflare bypass scenarios and can be managed from a single unified platform.
Scrapingbypass Proxy currently supports both HTTP and SOCKS5 proxy protocols, ensuring compatibility with most scraping tools, browsers, and automation frameworks.
Scrapingbypass Proxy uses a traffic-based billing model for both rotating residential and datacenter proxies. All traffic packages do not expire. You may request a free trial to evaluate Cloudflare bypass performance before purchasing.
Direct connections from mainland China IP addresses are not supported.
To use Scrapingbypass Proxy services, you must deploy a global network environment, such as a server or VPS located in Hong Kong or other overseas regions.
Desktop users may connect via a global network accelerator, while mobile users can access through a router configured with a global network environment.
If you are unable to set up a compatible global network environment, please do not proceed with a purchase.
Refunds are not available for unsupported direct connections.

Scrapingbypass API significantly improved our data extraction efficiency, especially for websites protected by Cloudflare. The API is straightforward, easy to integrate, and saved us countless hours dealing with anti-bot restrictions.
Since adopting Scrapingbypass API, bypassing Cloudflare challenges has become effortless. It handles captchas reliably and allows uninterrupted access to the data pipelines we depend on.
Scrapingbypass simplified our web data collection workflow by automatically handling complex Cloudflare verifications. It's fast, stable, and extremely reliable in production environments.
As a market analyst working with large-scale web sources, avoiding 403 errors is critical. Scrapingbypass API ensures consistent access to protected pages and delivers clean, usable data.
Scrapingbypass makes bypassing Cloudflare protection simple. The documentation is clear, the API behavior is predictable, and integration was completed in minutes. Highly recommended for developers.
I was initially skeptical, but Scrapingbypass exceeded expectations. It consistently bypasses Cloudflare human verification and has become a core component of our data infrastructure.

Scrapingbypass API Points Usage Concise Rules: 1 point per successful request, V2 version consumes 3 points. Points expire monthly and reset; recharge is separate. V2 supports JS polling, requires time-limited Proxy purchase. Max concurrent requests: 20/s. 403 or Access Denied may require Proxy configuration. Not compatible with selenium or Puppeteer; can be used with Anti-Detection Browsers and collectors.
View More
Scrapingbypass global Proxy is billed by data package, never expires. Supports payment methods such as Alipay, USDT. Data package usage includes upload + download data. Provides dynamic residential and Data Center Proxys, supports http and Socks5 proxy protocols. Free trial available after registration. Chinese users need to use it in Global environments as direct connection to mainland China IP is not supported.
View More
Bypass Cloudflare effortlessly with Scrapingbypass API for unhindered web data collection. It offers HTTP API and global Rotating Proxy services, supporting customizable browser fingerprints like Referer and UA for enhanced control. Scrapingbypass IP service settings cover FAQs, IP extraction tutorials, Anti-Detection Browsers, computer browsers, and mobile platforms. Detailed guides include configurations for various browsers and platforms.
View More
Bottom line: Direct fetch is enough for stable low-risk pages. Scrapingbypass API becomes more useful when monitoring jo...

Bottom line: Direct fetch is enough for stable low-risk pages. Scrapingbypass API becomes more useful when monitoring jo...
Bottom line: Direct fetch is enough for stable low-risk pages. Scrapingbypass API becomes more useful when monitoring jo...

When change alerts for veritaconnect.com suddenly increase, do not assume the site changed. Check retrieval quality, pag...

The choice between browser automation and an API access layer for veritaconnect.com should follow the interaction requir...
Bottom line: Direct fetch is enough for stable low-risk pages. Scrapingbypass API becomes more useful when monitoring jo...